Author
Marc Zollingkoffer
Director Software Engineering
bei SYZYGY Techsolutions
Lesedauer
8 Minuten
Publiziert
23. April 2024

AI wird die Entwicklung digitaler Lösungen revolutionieren. Sie wird bei der Ermittlung der Anforderungen bis hin zur QA unterstützen. Sie wird die Arbeit der Softwareentwickler teilautomatisieren und damit beeinflussen, wie Entwicklungsteams zusammenarbeiten. Und nicht zuletzt wird sie das Produkt selbst nachhaltig verändern.
In diesem Beitrag wollen wir uns auf den Aspekt konzentrieren, wie AI sich auf unsere Arbeit als Softwareentwickler auswirken wird. Speziell der Kern der Tätigkeit eines Entwicklers, das Coding, soll hier im Fokus stehen. Mit AutoDev und Devin kommen die ersten agentenbasierten Ansätze, um Softwareentwicklung mit Hilfe von AI zu automatisieren. Unterstellt, dass diese Ansätze erfolgsversprechend sind, sollten wir überlegen, wie groß unser AI Exposure, also die Auswirkung von AI auf unsere tägliche Arbeit, etwa durch Automatisierung und Aufgaben-Shifts, tatsächlich ist.
Am Ende zielt Softwareentwicklung darauf ab, lauffähigen und produktiven Code zu erzeugen, welcher sicher und effizient betrieben werden kann, damit für Anwender ein Nutzen gestiftet wird. Wie wir alle sehr gut wissen, ist aber viel mehr nötig, als nur Code zu programmieren, um dieses Ziel zu erreichen. Softwareentwicklung als Ganzes ist ein hochkomplexes Unterfangen, welches nicht selten genug auch schief geht. Requirements-Engineering, UX und UI-Design, Architektur und Software-Design, Teamdynamiken und Projektmethodiken, Testing, Nicht-Funktionale Anforderungen und Betriebsaspekte, all das muss zusammenspielen, um ein erfolgreiches Softwareprojekt zu liefern.
Viele Aufwände in einem Softwareprojekt entstehen also dadurch, weil Menschen gemeinsam innerhalb eines komplexen Prozesses miteinander interagieren. Wenn aber der Anteil der Menschen an diesem Prozess insgesamt durch Automatisierung verringert werden kann, verringern sich auch diese Aufwände.
Die Motivation mit Automatisierung hier anzugreifen und das Entwickeln von Software zu Verbilligen oder gar einen Teil der Investitionen in Softwareentwicklung als Toolanbieter für sich zu reklamieren, anstatt Entwickler zu bezahlen, ist groß.
Wie groß diese Motivation ist, kann man abschätzen, wenn man sich vergegenwärtigt, wie viele Softwareentwickler es weltweit gibt, und was diese grob zusammen ungefähr kosten. Hier sind nicht nur das Gehalt, sondern auch Lohnnebenkosten, Büroräume, Benefits, Dienstreisen etc. zu beachten. Nehmen wir also an, es arbeiten ca. 30 Millionen Entwickler weltweit an Softwareprojekten und im Schnitt kostet eine oder einer davon 100.000 € pro Jahr. Dann ist der Kuchen, um den es hier geht ca. 3.000.000.000.000 € groß. In Worten 3 Billionen (amerikanisch Trillions). Da sind selbst Krümel noch beachtliche Summen.
Ran an den Speck, ähm den Kuchen
AI-Assistenten und zunehmend autonome Agenten machen sich nun daran, diese Krümel aufzulesen oder sich gar einen kräftigen Bissen aus dem Kuchen zu genehmigen. Dabei zielen sie direkt auf den Kern der Softwareentwicklung: Die Erstellung von Code.
Im Gegensatz zu Coding-Assistenten wie Github Copilot zielen agenten-basierte Systeme wie AutoDev auf größere Teile der Wertschöpfungskette.
Tasks werden identifiziert, verstanden, implementiert, getestet und ready-to-merge als PR abgeliefert. Damit solche AI-Agenten erfolgreich sein können, müssen die Tasks eine entsprechende Qualität aufweisen. Denn sind wir ehrlich, selten sind Spezifikationen und Anforderungen komplett vollständig, so dass sie blind umgesetzt werden können. Der mitdenkende Entwickler wird gerne vorausgesetzt, um Lücken in den Requirements auszubügeln. Dies würde AI-Agenten noch schwerfallen, da Domänenwissen und “gesunder Menschenverstand” benötigt werden.
Ein verbessertes Requirements-Engineering kann diese Lücke aber verkleinern und mit Hilfe von engen und schnellen Feedback-Loops aus Implementierung und Abnahme oder Re-Spezifikation durch den Anforderer überwinden. Wenn Code-Anpassungen quasi instant durch AI möglich werden, dann sind solche schnellen Feedback-Loops durchaus vorstellbar.
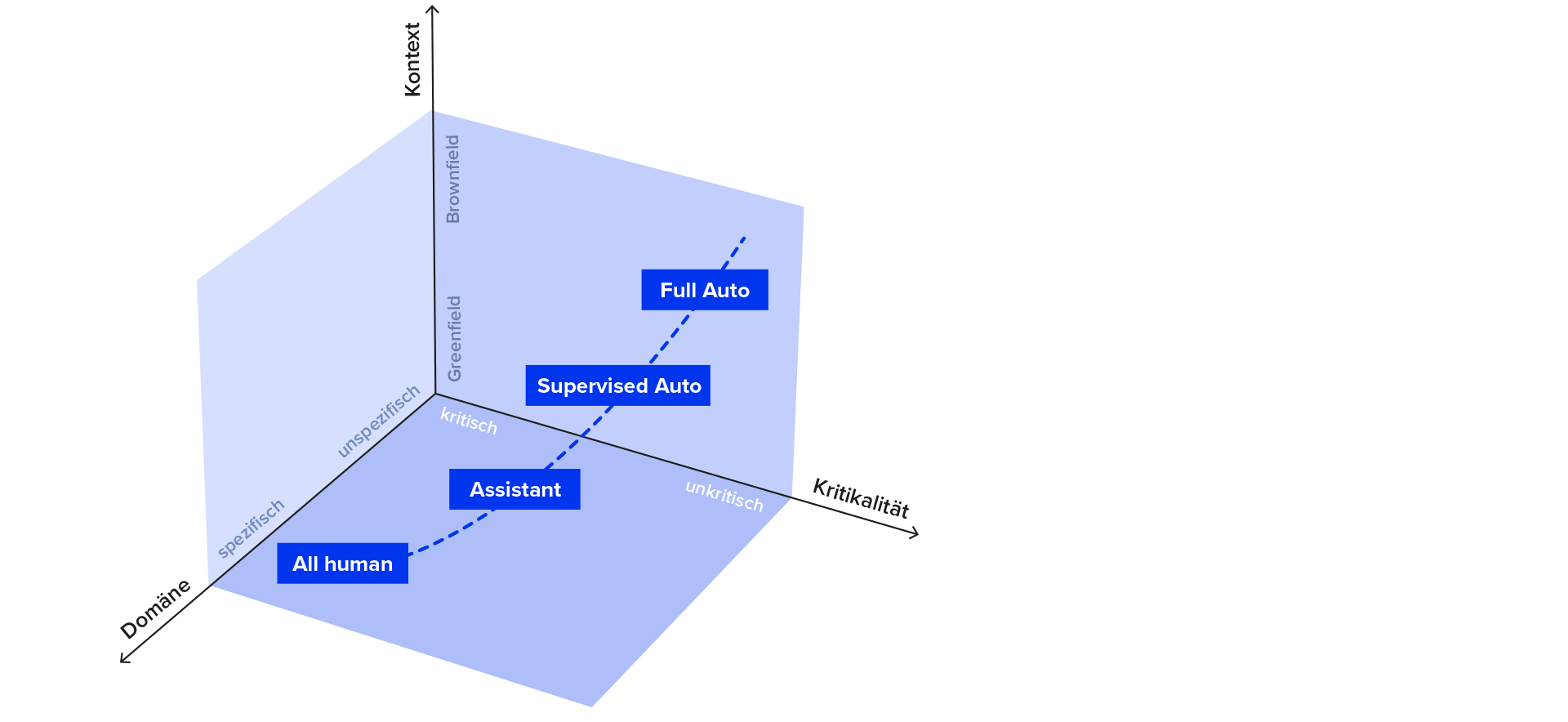
Voraussichtlich wird es aber zunächst einmal unterschiedliche Automatisierungsstufen geben.
All Human
Keine Unterstützung von AI. Alles noch von Hand gemacht.
Assistant
Der Mensch implementiert, der Assistent unterstützt beim Erstellen von Boilerplate und Test, etc. Im Wesentlichen das, was wir heute mit Copilot und Co schon im Einsatz haben.
Supervised Auto
AI erhält einen Task, kann diesen verstehen und die Spezifikation lesen. Der Code wird selbständig erzeugt, gestested und deployed. Allerdings werden Human-Feedback-Loops eingezogen, so dass die Anforderungen und in Folge die Implementierungen iterativ konkretisiert und verbessert werden.
Full Auto
Die AI arbeitet vollständig selbständig. Von der Anforderung zum laufenden Code ist kein menschlicher Eingriff mehr notwendig.
AI vs Human
Welchen und wieviel Code werden Menschen schreiben und/oder lesen? Dies wollen wir uns nun genauer ansehen.
Nicht alle Aufgaben, Anwendungstypen und -Teile werden sich in gleichem Maße eignen, um mittels AI automatisiert zu werden. Die folgende Abbildung trägt den Grad der Automatisierung nach 3 unterschiedlichen Dimensionen ab.
Vertiefen wir also diesen Gedankengang einmal weiter.
Kritisch vs unkritisch
Grenzen wir kritisch und unkritisch willkürlich als „es kann tatsächlich etwas kaputt gehen, z.B. Geld falsch überwiesen werden“ gegen „die Darstellung im UI ist nicht ganz korrekt“ voneinander ab.
Dann würde man einem AI-Agent eher nicht vertrauen, kritischen Code vollständig automatisiert umzusetzen. Zumindest bis auf Weiteres. Mit den bekannten Schwächen von LLMs, wie Halluzinieren, ist dies auch vollkommen verständlich, nachvollziehbar und richtig so. Für eher kritische Module wird also die Assistenten-Rolle von AI überwiegen. Anders sieht es allerdings aus, wenn es ich um unkritischen Code handelt. Hier ist vorstellbar, dass er vollautomatisiert nach gegebener Spezifikation erzeugt und dann auch gewartet wird. Das hieße, dass ein Mensch solchen Code mitunter überhaupt nicht mehr zu Gesicht bekommt. Die innere Qualität und Wiederverwendbarkeit würde dann auch keine Rolle mehr spielen. Relevant, ist dann nur das fertige Modul, das mit Tests ausreichend belegt der Spezifikation genügt.
Domänenspezifisch vs unspezifisch
Je spezieller die Domäne, umso schwerer wird sich eine AI tun, sinnvolle Ergebnisse zu erzeugen. Nicht spezifische und eher generische Teile, wie etwa die Aufbereitung und Versand einer E-Mail, können indes mit dem allgemeinen Weltwissen und unzähligen Codebeispielen, mit denen das Modell trainiert wurde, sehr gut bewältigt werden. Wahrscheinlich sogar besser, als im Durchschnitt durch menschliche Entwickler. Eine Maschine macht in der Regel einfach weniger Fehler und kann auf viel mehr Beispiele zurückgreifen, als dies menschlichen Gehirnen möglich ist. Diese hingegen zeichnen sich durch ihre Elastizität aus, was sie im Erlernen und Erdenken von neuen Dingen flexibler und nach wie vor überlegen macht.
Brownfield vs Greenfield
Zunächst kann man vermuten, dass Arbeiten im Brownfield stark automatisierbar sind. Diese sind in der Regel kleiner dimensioniert und betten sich in einen existierenden Kontext ein. Die AI kann sich aus diesem Kontext abschauen, wie Dinge zusammenhängen und wie sie umgesetzt wurden. Dies ist deutlich einfacher, als ein komplettes System neu zu denken und erstmalig zu erstellen. Die AI greift sich zum Beispiel einen Bugfix-Task, findet die entsprechende Code-Stelle, erstellt den Fix und einige Tests dazu. Sind die Tests grün, dann wird noch der PR gestellt und kann nach kurzer Review gemerged werden. Gleiches gilt für kleinere und mittlere Erweiterungen. Hier mag es sein, dass die ein oder andere Feedback-Schleife gefahren werden muss, aber der Mensch muss den Code eher nicht mehr anfassen. Im Greenfield wird die Assistentenrolle der AI im Vordergrund stehen, da hier der Kontext deutlich breiter und offener ist, und ein Gesamtverständnis eines mitdenkenden Entwicklers viel stärker gefordert ist.
Requirements-Engineering und Solution Architecture
Unser AI-Exposure ist also beachtlich und wir können somit erwarten, dass speziell die Bedeutung des Codens im Rahmen der Softwareentwicklung abnehmen wird. Dies wird nicht in allen Bereichen gleich schnell und gleich umfassend geschehen, aber über die Zeit immer weiter fortschreiten. Die Aufgabe von Menschen im Entwicklungsprozess wird sich daher in Richtung des Requirements-Engineerings und der Solution Architecture verschieben. Den Weg von Programmierer zum Solution Architekt habe ich in einem meiner früheren Artikel bereits umrissen. Wie es mit dem Requirements-Engineering weitergeht, sollten wir in einem den nächsten Beitrag näher und detailliert beleuchten.
Post Scriptum
Wir diskutieren lebhaft über das Thema und sind auch nicht immer in allen Punkten und Prognosen einer Meinung.
Bis auf eine Sache: Niemand kann wirklich mit Sicherheit wissen, wie genau AI sich in welchem Bereich auswirken wird. Aber dass sie eine fundamentale Auswirkung haben wird, damit rechnen wir fest.
Daher ist es so wichtig, dass wir wachsam bleiben und uns regelmäßig und nachhaltig mit der Thematik auseinandersetzen.
Einige der Fragen, die sich in der internen Diskussion zu diesem Post ergeben haben sind:
- Wäre nicht vielleicht doch das Greenfield mit einer klar abgesteckten Microservices Architektur das bessere Umfeld für eine hohe Automatisierung durch AI?
- Was ist für sehr komplexe Legacy-Anwendungen zu erwarten. Wird das Kontextfenster der AI groß genug sein, um diese vollumfänglich erfassen zu können?
- Was ist mit Low/No Code Plattformen.? Erleben sie durch AI einen weiteren Aufschwung oder werden sie gar verschwinden, wenn Code immer “billiger” wird?
Wir sind gespannt und werden es herausfinden.

Head of Technology