Die Verwendung von AI ist um Größenordnungen teurer als eine klassische Suche oder Webnutzung. Gut, wenn man die Kosten unter Kontrolle hält.
Author
Marc Zollingkoffer
Director Software Engineering
bei SYZYGY Techsolutions
Lesedauer
6 Minuten
Publiziert
26. November 2024

Die Nutzung von Large Language Models (LLMs) kann kostspielig sein, und nicht jeder Anwendungsfall rechtfertigt den damit verbundenen Aufwand. Besonders kritisch wird es, wenn KI-Modelle unkontrolliert eingesetzt werden, insbesondere in Verbindung mit Retrieval Augmented Generation (RAG). Dies kann schnell zu erheblichen Budgetüberschreitungen führen. Um die Kosten im Umgang mit LLMs zu kontrollieren, bietet Azure verschiedene Bordmittel an. Doch reichen diese aus, oder ist die zusätzliche Implementierung einer eigenen Kostenkontrolle sinnvoll? Anhand von zwei Szenarien möchten wir diese Frage untersuchen.
Azure-Bordmittel zur Kostenkontrolle
Azure stellt mehrere Werkzeuge zur Verfügung, um die Nutzung und die damit verbundenen Kosten von OpenAI-Services zu überwachen und zu begrenzen. Diese finden sich auf der Makro- wie auch auf der Mikroebene. Gemeinsam ist ihnen allen, dass sie nur begrenzt wirken und insbesondere auf der Makroebene nicht zwingend unmittelbar greifen, um eventuellen Schaden abwenden zu können. Gehen wir die Möglichkeiten einmal von klein nach groß durch:
Auf der Request-Ebene der Chat-Completions-API kann der Parameter `maxTokens` verwendet werden, um die Anzahl der Antwort-Tokens zu begrenzen. Allerdings beschränkt dieser Parameter nur die Tokens der Antwort, nicht aber die der Anfrage. In RAG-Szenarien ohne Prompt-Compression, in denen die Anfragen oft größer sind als die Antworten, ist diese Methode daher unzureichend, um Budgetüberschreitungen durch große Anfragen zu verhindern. Bei Verwendung der Assistant-API kann man indes `maxPromptToken` und `maxCompletionTokens` für einen Evaluations-Run eines Konversations-Strangs getrennt festlegen, was an dieser Stelle mehr Kontrolle zulässt.
Auf der Modell-Ebene kann ein Tokens-per-Minute-Limit (TPM) festgelegt werden, das bestimmt, wie viele Tokens pro Minute verarbeitet werden dürfen. Wird dieses Limit eng gesetzt, führt dies in der Praxis führt jedoch häufig zu HTTP-429-Fehlern, wenn das Limit für eine Minute droht, überschritten zu werden. Ein solches Verhalten beeinträchtigt die Nutzererfahrung natürlich eher negativ. Die Option „Enable dynamic quota“ erlaubt zwar eine temporäre Überschreitung des Limits, untergräbt aber die Kontrolle über die tatsächliche Nutzung und die entstehenden Kosten.
With dynamic quota, there is no call enforcement of a “ceiling” quota or throughput. Azure OpenAI will process as many requests as it can above your baseline quota. If you need to control the rate of spend even when quota is less constrained, your application code needs to hold back requests accordingly.
Auf der Service-Ebene des Azure OpenAI Service selbst können Quota-Alerts eingerichtet werden, die benachrichtigen, wenn bestimmte Nutzungsgrenzen überschritten werden. Zum Beispiel können Limits für die maximale Anzahl an Anfragen in einem Zeitraum festgelegt werden. Der Prüf- und Notifizierungsintervall kann hier recht eng auf 1 Minute gesetzt werden, was eine zeitnahe Benachrichtigung ermöglicht. Zudem kann man Limits für einzelne Modelle oder bestimmte Operationen definieren.
Eine Schwäche bleibt allerdings bestehen. Es handelt sich hier lediglich um Alerts. Dies bedeutet, dass keine automatische und direkte Aktion im System selbst erfolgt, wenn ein Limit überschritten wird. Reagiert niemand zeitnah auf einen Alert, kann trotzdem Schaden entstehen, da theoretisch einige Minuten ausreichen könnten, um hohe Kosten zu verursachen. Eine Möglichkeit hierzu bieten Actions. Wenn man für einen Alert über eine Action einen Webhook in den betroffenen Applikationen aufruft, kann dieser dann die Sperrung von weiteren Anfragen vornehmen. Dies setzt natürlich voraus, dass alle Client-Applikationen einen entsprechenden Webhook implementieren.
Universeller wäre eine dritte Instanz, die in der Lange ist, direkt und unmittelbar einzugreifen und unerwünschte Anfragen sofort und automatisch zu blocken, wenn sie die gesetzten Limits verletzen.
Ein solche Instanz wäre zum Beispiel ein Proxy, der zwischen Client-Applikation und AI-Service/Modell geschaltet ist.
Der Cost-Proxy als Lösung
Ein Cost-Proxy ist ein vorgeschalteter Reverse-Proxy, der Anfragen an den Azure OpenAI-Service weiterleitet und dabei verschiedene Kontrollfunktionen übernimmt. Er kann die Größe der Anfragen überprüfen und solche mit zu vielen Tokens ablehnen, bevor sie Kosten verursachen. Außerdem kann er die Anzahl der Anfragen pro Zeitraum begrenzen und spezifische Limits für einzelne Nutzer oder Anwendungen setzen und mit einer zeitnahen Kalkulation der auflaufenden Kosten weitere Requests unterbinden, wenn Schwellwerte überschritten werden.
Insbesondere für oben beschriebene Azure Alerts kann ein solcher Proxy an zentraler Stelle Webhooks bereitstellen und je nach Alert spezifische Services blockieren und auch wieder freischalten, wenn der Alert resolved wurde.
Weitere und komplexere Checks, wie etwa Bot-Erkennung, wären denkbare Ausbaustufen.
Durch die Erweiterung der Antworten um Kosteninformationen erhalten die Nutzer zudem Transparenz über ihren Verbrauch. Dies alles kann global wie auch per Client-App ausgesteuert werden.
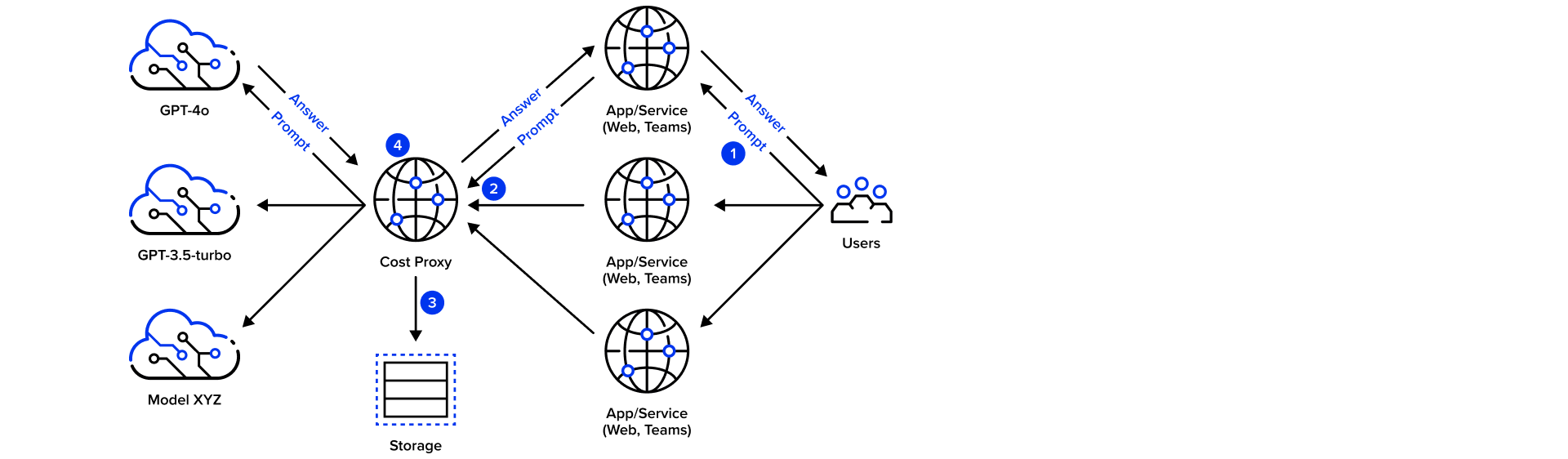
- Der Request, der an die App gesendet wird, wird über den Proxy zur Inferenz an das Modell weitergeleitet.
- Die Anfragen werden überprüft, ob ein Limit überschritten wurde.
- Die Anfragen, einschließlich des Tokenverbrauchs und der damit verbundenen Kosten, werden in einem persistenten Speicher protokolliert.
- Die Antwort wird mit Informationen zu Kosten der Anfrage angereichert.
Der Proxy übernimmt somit an zentraler Stelle allgemeine Überwachungsaspekte und befreit die Client-Applikationen von diesen Aufgaben.
Zum Tracking der Kosten schreibt der Proxy die Anfragen und die damit verbundenen Kosten in einen kostengünstigen, persistenten Speicher wie Azure Tables. Auf dieser Basis kann zusätzlich ein detailliertes Reporting aufgesetzt werden, um den Verbrauch genau zu analysieren und bei Bedarf Maßnahmen zu ergreifen.
Betrachten wir nun 2 Szenarien und bewerten die diese mit Blick auf die Kostenkontrollmöglichkeiten.
Szenario 1: Interne Applikation für einen ausgewählten Benutzerkreis
In diesem Szenario handelt es sich um eine interne Anwendung mit etwa 100 Nutzern. Jeder Nutzer stellt durchschnittlich eine Anfrage pro Stunde, acht Stunden am Tag, an 20 Tagen im Monat. Das ergibt insgesamt 16.000 Anfragen pro Monat. Bei einer durchschnittlichen Anfragegröße von 4.000 Tokens und einer Antwortgröße von 800 Tokens belaufen sich die monatlichen Kosten auf etwa 17 € (natürlich varieren diese Werte, je nach Token-Preis des zugrundeliegenden Modells. Hier geht es aber eher um Größenordnungen).
Bewertung des Szenarios
Die Gesamtkosten sind in diesem Fall relativ gering. Die vorhandenen Azure-Bordmittel zur Kostenkontrolle sind ausreichend, um die Nutzung zu überwachen und bei Bedarf Anpassungen vorzunehmen. Da die Nutzerzahl auf einen internen Personenkreis beschränkt ist und die Anzahl der Anfragen überschaubar sind, ist das Risiko von plötzlichen Kostenexplosionen überschaubar. Man kann ein recht enges TP-Limit setzen und muss nicht befürchten, dass die User-Experience darunter leiden wird, noch dass dieses Limit über beispielsweise Bots gesprengt werden kann. Der zusätzliche Aufwand für die Implementierung eines eigenen Cost-Proxys steht in keinem sinnvollen Verhältnis zu den möglichen Einsparungen. Daher ist ein Cost-Proxy hier nicht notwendig.
Szenario 2: Öffentliche Applikation für einen größeren Benutzerkreis
In diesem Szenario betrachten wir eine öffentliche Anwendung mit 100.000 Nutzern. Jeder Nutzer stellt durchschnittlich 0,1 Anfragen pro Stunde, 16 Stunden am Tag, an 30 Tagen im Monat. Das führt zu insgesamt 4.800.000 Anfragen pro Monat. Mit den gleichen Token-Größen wie im ersten Szenario belaufen sich die monatlichen Kosten auf etwa 5000 €.
Bewertung des Szenarios
Hier sind die Kosten erheblich höher, und die öffentliche Natur der Anwendung macht es schwierig, das Nutzungsverhalten der Nutzer genau vorherzusagen oder Bots mit absoluter Sicherheit auszuschließen. Es besteht ein erhöhtes Risiko für unvorhersehbare Nutzungsmuster und sogar Missbrauchspotenzial, da ohne Kontrolle böswillige Akteure die Anwendung für massenhafte Anfragen nutzen könnten. Spitzenlasten oder unerwartet hohe Nutzeraktivität können die Kosten schnell in die Höhe treiben. Die begrenzte Wirksamkeit der Azure-Bordmittel bietet in diesem Kontext nicht die notwendige Granularität und Reaktionsgeschwindigkeit, um die Kosten effektiv zu kontrollieren.
In diesem Szenario stoßen die Azure-Bordmittel an ihre Grenzen. Die Implementierung einer eigenen zusätzlichen Kontrollinstanz – wie die eines Cost-Proxys – wäre daher sinnvoll, um die Kosten unter Kontrolle zu halten und die Anwendung vor Missbrauch zu schützen.
Fazit
Die Entscheidung für oder gegen die Implementierung eines Cost-Proxys hängt maßgeblich vom jeweiligen Anwendungsszenario ab. In kleineren, internen Anwendungen wie in Szenario 1 sind die vorhandenen Azure-Bordmittel ausreichend, und der zusätzliche Aufwand für einen Cost-Proxy ist nicht gerechtfertigt. In öffentlichen Anwendungen mit hohem Nutzeraufkommen und entsprechend hohen Kosten, wie in Szenario 2, ist ein Cost-Proxy hingegen nahezu unerlässlich. Er bietet eine effektive Möglichkeit, die Kosten unter Kontrolle zu halten, schützt vor Missbrauch und trägt zur Stabilität und Wirtschaftlichkeit der Anwendung bei.
Empfehlungen
- Analyse des Nutzungsszenarios und Beurteilung der Nutzerzahl, das erwartete Nutzungsverhalten und die potenziellen Risiken der Anwendung.
- Einsatz von Azure-Bordmitteln und Nutzung der vorhandenen Tools zur Überwachung und Kontrolle, wo sie ausreichend sind.
- Implementierung eines Cost-Proxys für öffentlichen Anwendungen, um effektive Kostenkontrolle und Schutz vor Missbrauch zu gewährleisten.
- Kontinuierliches Monitoring mit regelmäßigem Reporting und Echtzeitüberwachung, um den Verbrauch stets im Blick zu haben und schnell auf Veränderungen reagieren zu können.
Durch eine sorgfältige Analyse und den gezielten Einsatz von Kontrollmechanismen kann man sicherstellen, dass KI-Anwendungen sowohl leistungsfähig als auch kosteneffizient sind. So werden unerwartete Kosten vermieden und gleichzeitig eine hohe Nutzerzufriedenheit gewährleistet.

Head of Technology