a.k.a Frankenstein-Formular mit viel zu vielen Daten
Autor
Dominik Petschenka
Software Architect
bei SYZYGY Techsolutions
Lesedauer
5 Minuten
Publiziert
28. August 2023

Wir bauen maßgeschneiderte Software. Zu unseren Aufgaben gehört es, individuelle Business Prozesse umzusetzen. Damit einher gehen zuweilen knifflige Aufgabenstellungen an Konzept und Implementierung, etwa sehr große Formulare. Der Artikel gibt Einblick in die Lösungsfindung einer dieser (nicht) alltäglichen Herausforderungen: Wie setzt man ein Formular um was nicht existieren sollte?

Die Aufgabe
Für einen unserer Kunden betreiben wir eine Vertriebsplattform auf der Partner- und Provisionsdaten verwaltet werden. Im Rahmen aktueller Erweiterungen sollte ein Prozess von Excel auf eine web-basierte Variante umgestellt werden.
Im konkreten Fall ging es um die schnelle Bearbeitung von umfangreichen Reklamations-Tickets.
Ein Reklamations-Ticket besteht aus diversen Kopfdaten sowie Einzelpositionen. Jede Position besteht aus mehreren Auswahlfeldern und Freitextfeldern. Dazu kommen 10 Read-Only Felder (reine Anzeige zur Information).
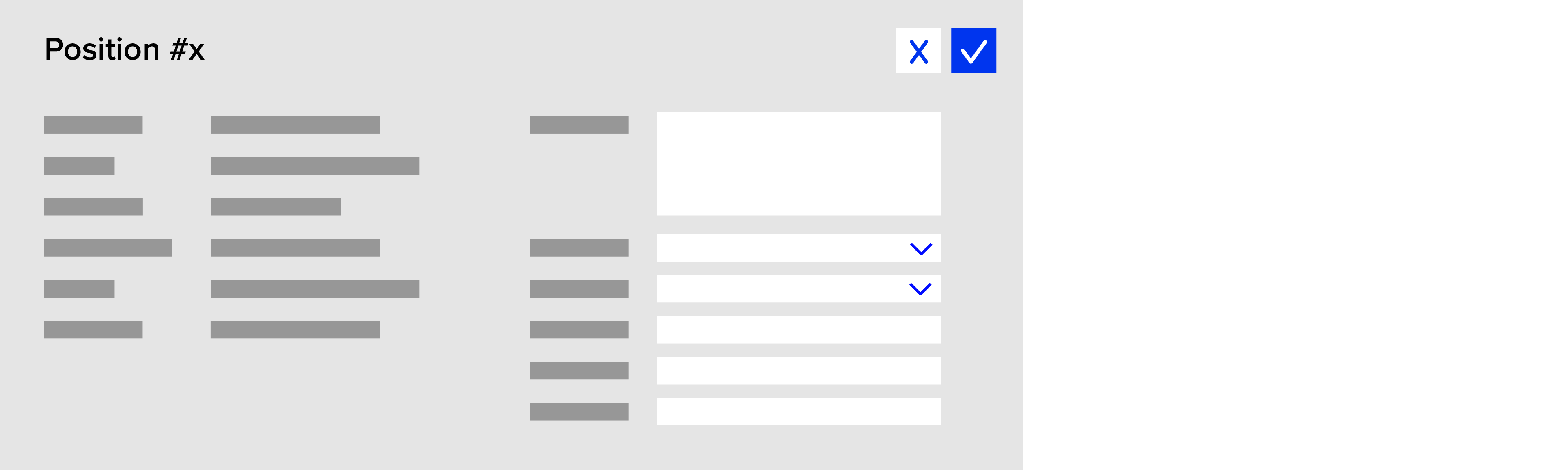
Formular – Einzelne Position
Soweit, so gut. Kompliziert wird es zunächst durch die schiere Menge an Positionen. Denn ein Ticket kann bis zu 500 Positionen enthalten. Bei 6 Eingabefeldern + 10 Read-Only Feldern pro Position heißt das: Das Formular enthält sehr viele Datenfelder:
10*500 + 6*500 = 8.000 Datenfelder
Zusätzlich musste dem Benutzer eine Möglichkeit gegeben werden, jederzeit beliebige Positionen in den Viewport zu holen. Das ist notwendig, da die Bearbeitung einer Position oft von anderen Positionen abhängt, die – bei 500 Positionen – im Regelfall gerade nicht sichtbar sind.
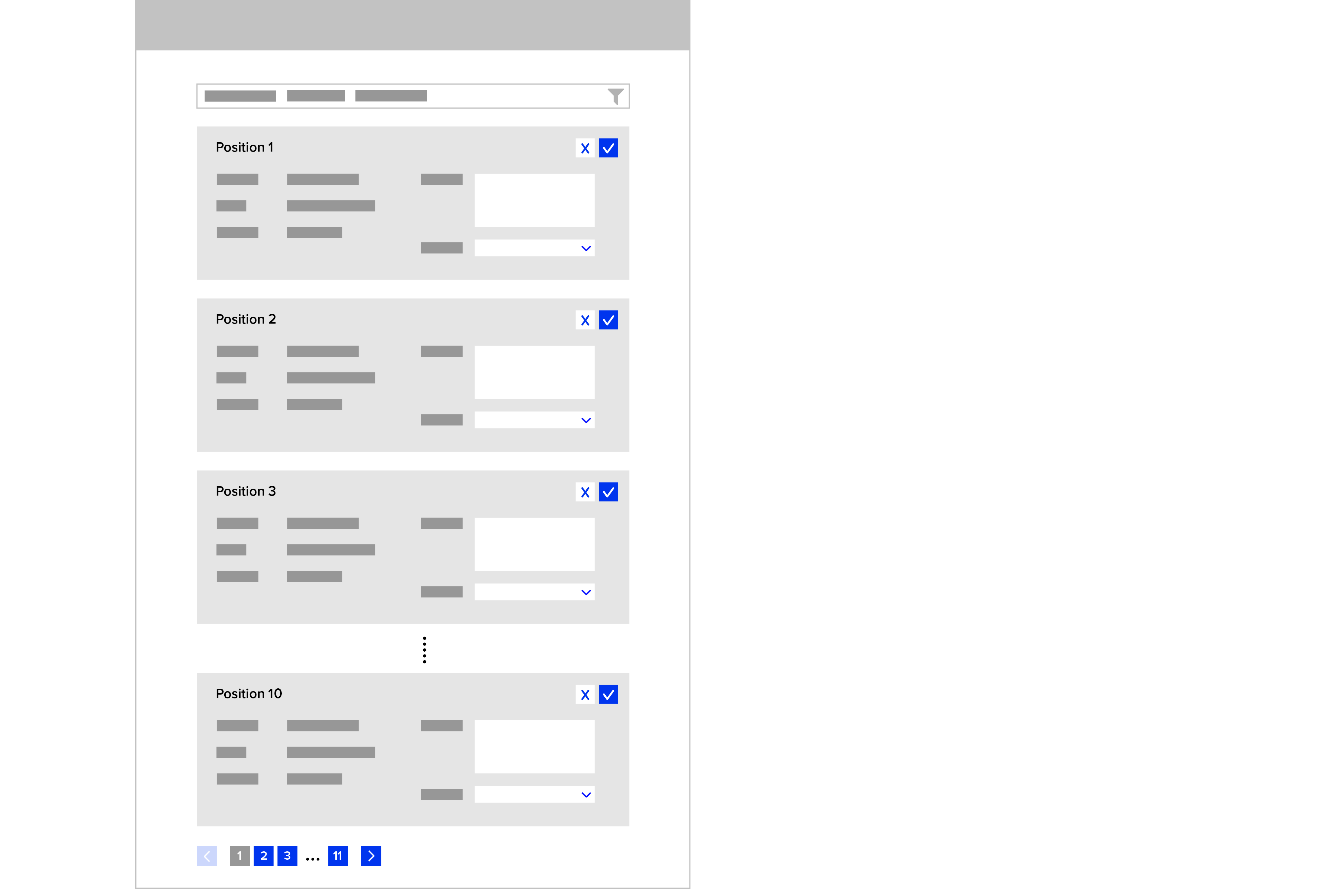
Formular – Gesamtes Ticket mit mehreren Positionen (gekürzt)
Man kann sich vorstellen, dass dies schnell unübersichtlich wird. Im Web-Umfeld ergeben sich dazu weitere Herausforderungen. So können Daten verloren gehen, wenn die Session abläuft. Zusätzlich ist diese Menge an Feldern, die auch untereinander Beziehungen haben, auch eine Herausforderung für die Performance, wenn alles gleichzeitig am Client verarbeitet werden soll. Und was alles noch passieren kann.
Das Konzept
Kurzum: Die Benutzer sollen also große Datenmengen möglichst komfortabel und performant bearbeiten können.
Meistens haben Listen bei diesem Kunden Endlos-Scrolling. Bei dieser Datenmenge wäre das jedoch nur mit Virtualisierung performant umsetzbar. Die Umsetzung wäre mit unseren Rahmenbedingungen jedoch sehr aufwendig. Wir haben uns daher aus pragmatischen Gründen für klassisches Paging entschieden. Zudem bietet Paging mit klar definierten „Seiten“ eine bessere Orientierung für User. Man kann sich als User leichter merken, dass man auf „Seite 5“ weiterarbeiten muss als „ungefähr drei Meter weit runtergescrollt müsste es gewesen sein“.
Ganz grob ergibt sich folgendes Konzept:
- Für mehr Übersicht und gleichzeitig als Lösung für das Performance-Problem sorgen Filter und eine Blätter-Funktion
- Der User soll alle Daten filtern können: D.h. er kann auch Daten filtern, die er gerade eingegeben aber noch nicht gespeichert hat
Wir wenden also Konzepte aus Listen die meistens reine Lesesichten sind, auf ein Formular an. Daraus ergeben sich einige technische Herausforderungen. Wie können wir Paging und Filter mit der Möglichkeit alle Daten jederzeit bearbeiten zu können zusammenbringen?
Die Lösung
Ein zentraler Punkt der Lösung ist ein temporärer Store, in dem alle Änderungen gehalten werden, auch, bevor sie endgültig gespeichert werden. Damit bleiben Eingaben erhalten, auch wenn die Datensätze aufgrund von Filterung oder Seitenwechsel nicht angezeigt werden. Mit dem temporären Store ergeben sich folgende Detailfragen:
- Wollen wir alle Daten laden und im Client halten?
- Wollen wir den temporären Store für ungespeicherte Änderungen im Client halten?
Die Beantwortung dieser Fragen hängt stark zusammen. Werden alle Daten im Client gehalten, kann man im Browser filtern und blättern und benötigt weniger Anfragen an den Server. Alle Daten direkt zu Laden machte den initialen Request jedoch sehr langsam. Deshalb wollen wir die Daten nur in Häppchen laden.
In Konsequenz wollen wir auch unseren temporären Store am Server halten. Es hat zwar den Nachteil, dass alle Änderungen immer und sofort zum Server gesendet werden müssen. Der Vorteil ist aber, dass alle Operationen an einer Stelle, der „Single Source of Truth“ stattfinden. Das beinhaltet auch alle Validierungen, die sowieso immer nochmal am Server durchgeführt werden sollten um Manipulation oder Client-Fehlern entgegenzuwirken. Wenn der temporäre Speicher am Server persistiert wird, ist er zudem auch vor Session-Verlust etc. geschützt. So können wir dem User auch eine Wiederherstellungsfunktion anbieten, wenn er zurückkommt.
Als weiteres, nicht unerhebliches Kriterium für einen Server-Store ist die Anforderung, paralleles Arbeiten an den Daten zu verhindern, damit User sich nicht gegenseitig Daten überschreiben können. Wir wissen so jederzeit, ob der Datensatz sich bei einem User in Bearbeitung befindet, wenn ein zweiter User den Datensatz öffnet. In dem Fall können wir die Bearbeitung für den zweiten User sperren so lange der erste ihn bearbeitet.
Nach Abwägen von Für und Wider sind wir bei folgender Lösung angelangt:
- Wir laden und zeigen immer nur eine „Seite“ (10 Positionen):
Damit ist Performance kein Problem. Zudem hat der User immer eine Orientierung wo er sich gerade befindet - Jede Eingabe wird direkt in einem temporären Store gespeichert:
Dies löst das Problem, dass die Daten beim Blättern oder Filtern verloren gehen können - Beim Blättern und Filtern werden immer die aktuellen temporären Daten angezeigt
- Per Speicher-Button werden die temporären Eingaben endgültig gespeichert:
User haben damit selbst in der Hand, wann sie ihre Daten endgültig speichern möchten - Rudimentäre Clientside-Validierung für die sichtbaren Daten (aktuelle Seite):
Damit können wir sofort Feedback bei der Eingabe geben - Backend-Validierung für alle Daten beim Klick auf “Speichern”:
Da wir nicht alle Daten im Frontend halten und eine verlässliche Validierung sowieso im Backend stattfinden muss, implementieren wir sie in diesem Fall nur dort
Die Umsetzung
Folgender Tech-Stack kommt beim Kunden zum Einsatz:
- React
- Final Form
- GraphQL
- .Net Core
Datenanbindung
Wir verwenden GraphQL für alle Anbindungen an das Backend. Beim Aufruf des Datensatzes wird zuerst eine Anfrage getTemporaryKey(ticketId) gesendet. Der zurückgegebene TemporaryKey wird jetzt bei allen weiteren Anfragen mitgesendet. Als nächstes werden die ersten 10 Positionen geladen. Dazu wird der TemporaryKey mit übergeben:
getTicketPositions(ticketId, temporaryKey, page).
Bei der Eingabe werden die geänderten Felder zum Server gesendet und in den temporären Store geschrieben.
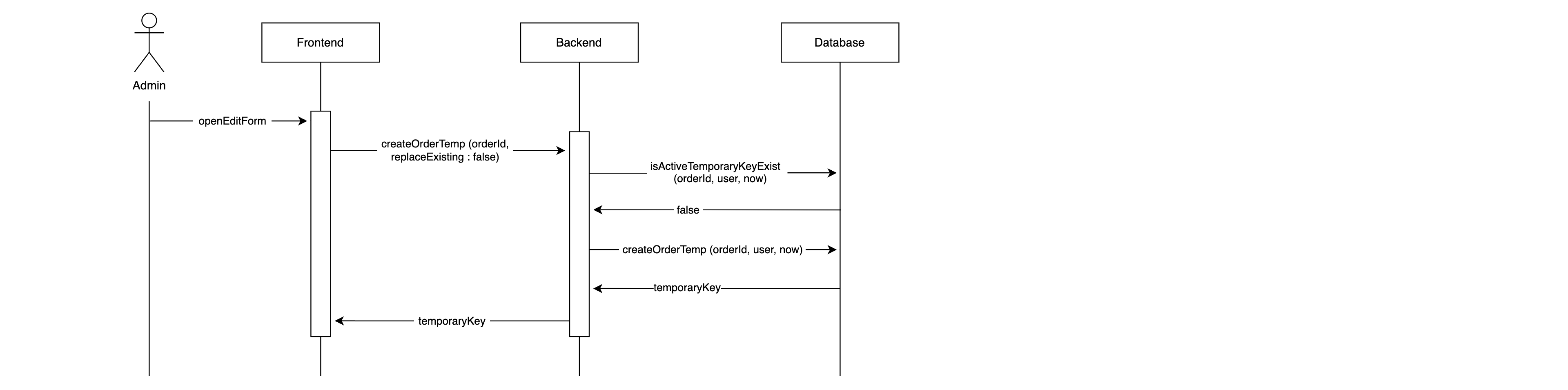
Formular – temporärer Store
Auch beim Paging, Filtern oder Sortieren wird der Temporary Key mitgesendet. So können serverseitig die Datensätze aus der Datenbank mit eventuell vorhandenen temporären Eingaben angereichert und zurückgegeben werden.
Frontend
Das Frontend ist in React geschrieben. Eine übergreifende Komponente kümmert sich um die Verwaltung und das Laden der Daten. Sie rendert alle Positionen und gibt jeweils nur die Daten von einer Position nach unten in ihr Position-Formular. Das Formular für eine Position ist eine Subkomponente. Hier werden nur die Daten einer Position verwaltet.

Formular – React Komponenten
Natürlich wollen wir nicht bei jedem Tastendruck eine Anfrage zum Server senden, und auch nicht bei grob ungültigen Eingaben. Daher benutzen wir React Final Form für das State Management und die Validierung im Formular.
Um kleine Päckchen performant behandeln zu können, erkennen wir Veränderungen bezogen auf die Position mit einem React Effect. Der Effect prüft ob Values in einer Position verändert wurden und speichert sie bei Bedarf. Die Methode saveTemp ist eine GraphQL Mutation. Wir haben sie noch debounced damit nicht mehrere Netzwerk-Anfragen in kurzer Zeit gesendet werden. Debounce (und das verwandte Throttling) ist eine Technik um mehrere Aktionen, die in einem definierten Zeitfenster stattfinden (z. B. mehrere Tastenanschläge) zusammenzufassen. So kann nach dem letzten Tastenanschlag der Speichervorgang ausgelöst werden und nicht bei jedem einzelnen.
const saveTempDebounced = useRef(debounce(saveTemp, 300)).current;
const previousValues = usePrevious(positionValues);
useEffect(() => {
if (!isEqual(positionValues, previousValues)) {
saveTempDebounced(positionValues);
}
}, [positionValues, previousValues]);
Die Mutation für saveTemp nimmt die Ticket ID, den Temporary Key und die Eingaben der Position entgegen.
mutation TicketPositionSaveTemp(
$ticketId: Int
$temporaryKey: Guid
$positionData: TicketPositionInput
) {
ticket {
saveTicketPositionTemp(
ticketId: $ticketId
temporaryKey: $temporaryKey
positionData: $positionData
) {
errorMessage
successful
}
}
}Solange es keinen Fehler gibt, muss nicht weiter auf die Rückgabe der Mutation reagiert werden. Damit sind die Daten alle bereits auf dem Server (temporär) gespeichert.
Die Eingaben können jederzeit per Button-Klick in den dauerhaften Speicher übernommen werden. Dafür wird eine weitere Mutation verwendet. Da die Daten bereits am Server sind, müssen für das endgültige Speichern nur noch Ticket ID und der Temporary Key übergeben werden:
mutation TicketSave(
$ticketId: Int
$temporaryKey: Guid
) {
ticket {
save(
ticketId: $ticketId
temporaryKey: $temporaryKey
) {
errorMessage
successful
}
}
}Die Daten werden damit endgültig am Server in der Datenbank gespeichert. Der Datensatz wird dann für andere User entsperrt und die Bearbeitung ist beendet.
Fazit
Die Anforderung war hier sicherlich eine ganz spezielle. Soweit möglich, sollte immer versucht werden, die Menge der angezeigten Daten zu reduzieren. Das sorgt meistens für bessere Usability und hilft viele der oben genannten (wenn auch gelösten) Probleme direkt zu vermeiden.
In unserem Fall war dies keine Option: Alle 8.000 Datenfelder sollten zeitgleich und in Abhängigkeit voneinander bearbeitet werden können. Nach Abwägen der verschiedenen Vor- und Nachteile und der ganz eigenen Anforderungen in diesem Projekt haben wir eine für uns und den Kunden passende Lösung gefunden.
Die Anwendung ist jetzt seit einigen Monaten in Betrieb, die User sind zufrieden und es gab (noch) keine größeren Bugs – Mission accomplished 😉

Head of Technology