Retrieval Augmented Generation erschließt Unternehmensdaten neu
Autor
Michael Wolf
Head of Technology
bei SYZYGY Techsolutions
Lesedauer
6 Minuten
Publiziert
13.09.2024

Retrieval Augmented Generation (RAG) verspricht einen neuen, einfachen Zugang zu Informationen, der über den Komfort einer klassischen Suche hinausgeht. Es ist davon auszugehen, dass diese Art der Informationsbereitstellung in Zukunft in allen Content-Plattformen Einzug halten wird. Wir nähern uns RAG mit einem speziellen Blick auf die Erschließung von (unstrukturiertem) Unternehmenswissen für Mitarbeitende.
Data
Jedes Unternehmen hat eine Vielzahl von internen Daten, die Mitarbeitenden so einfach wie möglich zugänglich gemacht werden sollen. Idealerweise zentralisiert. Doch schon die Verwaltung der (richtigen) Daten kommt mit Herausforderungen:
- Das Zusammentragen der Informationen ist nicht trivial. Welche Informationen sind vorhanden, brauchbar und relevant?
- Daten liegen unstrukturiert, verteilt und in unterschiedlichen Formaten vor: PDF, Word, Intranet-Seiten, Bilder, Diagramme, Markdown sind nur einige Beispiele. Nicht alle dieser Formate unterstützen gleichermaßen gut eine schnelle und zielgerichtete Suche nach relevanten Informationen.
- Auch über die Auswahl des richtigen technischen Trägers lässt sich trefflich streiten: Nutzt man ein CMS, ein Wiki oder eine Kombination aus unterschiedlichen Systemen? Schnell führt dies zu technischen Diskussionen über Data Lakes, Warehouses und mehr.
- Zuletzt ist Data Governance erforderlich, von der Definition der Ownership über Zugriffskonzepte bis hin zum Sicherstellen der Aktualität und Relevanz der Daten über die Zeit.
Diese Herausforderungen adressieren viele Unternehmen im Zuge ihrer Digitalisierungs-Strategie und Data & Analytics. Dabei kommt irgendwann die Frage auf, wie auf die Informationen zugegriffen bzw. gesucht werden kann und wie Ergebnisse präsentiert werden sollen. Eine Antwort ist knifflig, denn:
- Wie Nutzer:innen suchen (wollen) ist sehr individuell. Die eine „stöbert“ für ihr Leben gern und erfreut sich über jeden noch so individuellen Filter, während eine andere „nur“ ein einziges intelligentes Suchfeld nutzen will.
- Als Suchergebnis präferieren einige Nutzer:innen reinen Text, andere Bulletpoint-Listen, Tabellen oder gleich alles in Word oder Excel. Wieder andere wünschen sich Ergebnisse in weiter verarbeitbaren Formaten wie etwa JSON.
- Auch die benötigte Detailtiefe der Inhalte ist individuell: Mal sind Ergebnisse mit vollumfänglichen Details, mal eine Zusammenfassung, manchmal wenige High-Level-Stichpunkte hilfreich.
Die ideale Lösung wäre eine Suche nach beliebigen Informationen innerhalb beliebiger Formate. Mit dynamischen, den individuellen Wünschen der Nutzer:innen angepassten Antworten sowie einem für alle gleichermaßen nutzbaren Interface (z.B. natürliche Sprache).
Hier kommt Retrieval Augmented Generation (RAG) ins Spiel…
Chatbot Renaissance
Generative KI hält in immer mehr Tools und Services Einzug, neue Einsatzgebiete finden sich täglich. Vor allem die Integration und Nutzung von Sprachmodellen in Form von Chats oder Assistenten schreitet schnell voran.
Während sich Chats schon seit Jahren als beliebtes Kommunikationsmittel zwischen Personen etabliert haben, waren Einsatzgebiet und Erfolg von Mensch-Maschine-Chats überschaubar. Dies hat sich mit ChatGPT & Co schlagartig geändert, so gut wie jede:r nutzt diese maschinellen Antwort-Systeme. Das liegt vor allem daran, dass Sprachmodelle in der Lage sind, mit Nutzer:innen in natürlicher Sprache zu kommunizieren und sie (vermeintlich) zu verstehen. Auch die Möglichkeit durch angepasste Prompts Antworten in die gewünschte Richtung lenken zu können, führt zu großer Akzeptanz.
Dieses Sprachvermögen sowie die Flexibilität bezüglich der Ausgabe auch in bestehenden Content-Plattformen wie z.B. in internen Wikis zu integrieren, liegt nahe. Wenn diese Systeme zudem kontextabhängig fundierte, fachspezifische Antworten liefern könnten, etwa zu internen Prozessen eines Unternehmens, hätte man den idealen Assistenten.
Proprietäre Daten
Large Language Models (LLMs) haben enormes Wissen bzw. einen großen Sprachschatz, denn sie sind mit einer riesigen Menge von öffentlich zugänglichen Daten trainiert. Um Antworten zu speziellen Informationen wie etwa Unternehmensinterna liefern zu können, muss dieses proprietäre Wissen vorliegen. Wie also bringt man LLMs dieses Wissen bei?
Die naheliegendste Variante, wie ein Sprachmodell domänenspezifisch antworten kann, ist das (Re-) Training oder Finetuning. Dies ist jedoch verhältnismäßig zeit- und rechenintensiv. Zudem ist das Wissen immer nur so aktuell, wie das letzte Training zurückliegt. Gerade bei domänenspezifischen Fragen ist Datenaktualität aber wichtig.
In der Praxis erweitern Nutzer:innen das Sprachvermögen von LLMs daher oft „manuell“ mit speziellen Daten (Prompt Engineering). Sie schicken Kontext und fachliche Informationen im Prompt mit und lenken Antworten damit in eine bestimmte Richtung, ganz ohne Finetuning. Ein Erschließen von unbekannten fachlichen Details (klassische Suche) ist damit aber nicht möglich. Denn hier müssen Nutzer:innen bereits zum Zeitpunkt des Prompts über das gesamte Fachwissen verfügen.
Search & Retrieval
Einen guten Ansatz im Umgang mit proprietären Daten verspricht Retrieval Augmented Generation. Es kombiniert die Stärken von klassischer Suche und abfragebasierten Modellen mit den Fähigkeiten generativer Modelle.
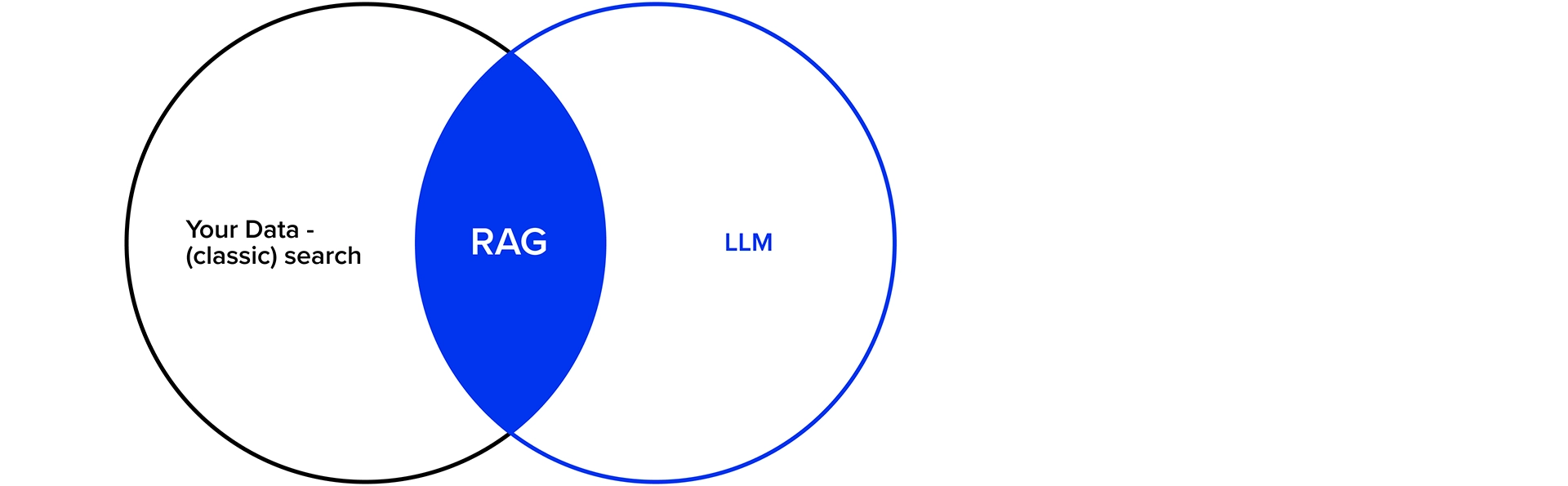
In der Regel wird RAG mit einer semantischen Suche und Vektor-Datenbanken realisiert. Vereinfacht werden relevante Daten mittels Chunking & Embedding in kleinere Einheiten aufgeteilt (Chunks) und inklusive multidimensionaler Vektor-Informationen (Embedding) in der Datenbank hinterlegt. Bei einer Suchanfrage wird zunächst ein Query Embedding erstellt anhand dessen semantisch nach passenden Chunks in der Datenbank gesucht wird. Das Ergebnis wird dem initialen Prompt hinzugefügt und erst dann wird das Sprachmodell angefragt.
Damit ist man – salopp gesagt – in der Lage mit diesen Daten (z.B. allen internen Dokumenten eines Unternehmens) zu chatten. Man kann Fragen frei formulieren, inklusive Wünschen bezüglich Format, Sprachstil und Detailtiefe der Antworten. Dank Embeddings und semantischer Suche ist i.d.R. selbst die Sprache an sich variabel. Z.B. könnten Daten in Englisch und Deutsch vorliegen und die Frage in Spanisch formuliert sein.
RAG
Das folgende Beispiel beschreibt eine mögliche Umsetzung von RAG auf Basis unseres internen Wikis mit Hilfe der Microsoft Azure Cloud Services. Zentrale Bausteine sind hier Azure OpenAI und die Azure Search Services.
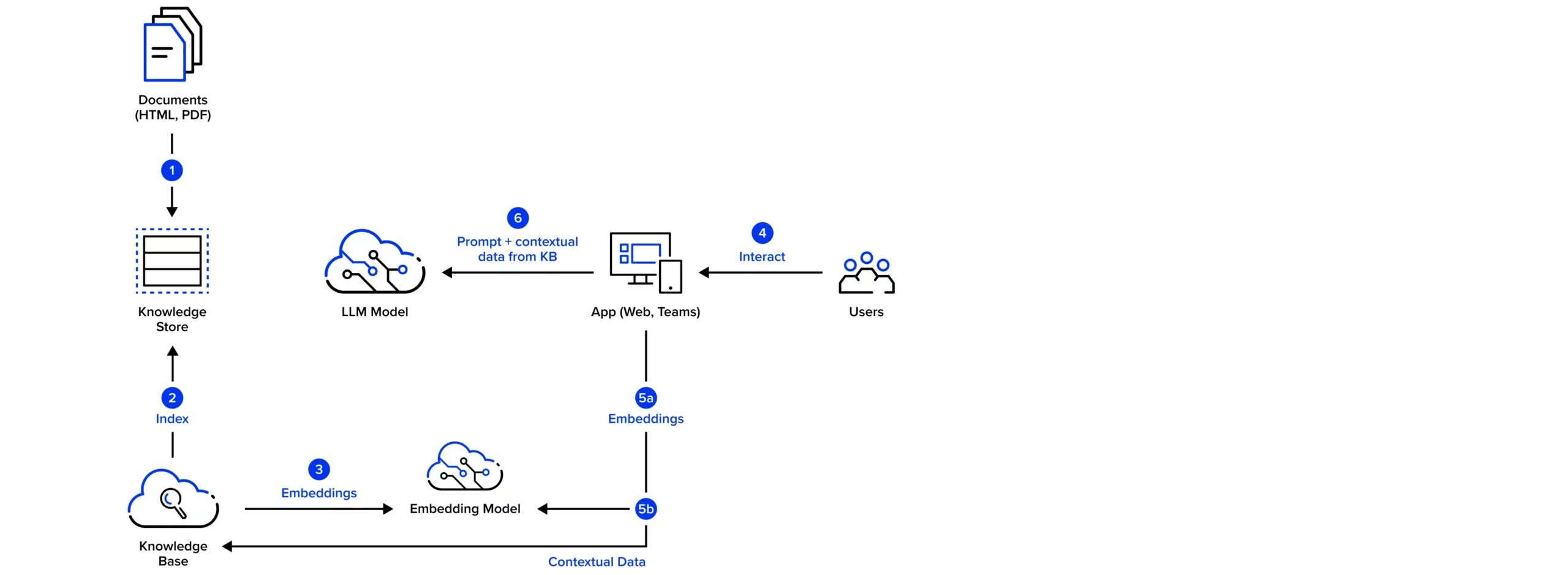
- Die Dokumente aus unserem Wiki und der Homepage werden in einen Blob-Storage-Container hochgeladen.
- Wir verwenden einen Azure Search Service für unsere Knowledge Base. Die Dokumente werden dazu aus dem Knowledge Store mit Hilfe eines Indexers in kleine Chunks aufgeteilt und dann in einen Suchindex überführt.
- Neben der klassischen Volltextindizierung nutzen wir ein Embedding-Modell, um die Chunks zu vektorisieren. Damit ermöglichen wir eine semantische und sprachenübergreifende Suche.
- Über die UI einer (Web-)App interagieren die Nutzer:innen mit dem Modell und der Knowledge Base, indem sie zum Beispiel Fragen stellen.
- a) Die Fragen (oder das Prompt) werden ebenfalls als Vektor enkodiert.
b) Das Prompt wird mit Hilfe der semantischen Suche um weitere Informationen aus den Chunks der Knowledge Bases kontextbezogen angereichert. - Schließlich wird ein geeignetes LLM – z.B. GPT-35-turbo, GPT-4o oder GPT-4o-mini – mit dem erweiterten Prompt aus Frage und den kontextbezogenen Inhalten angefragt. Unter Berücksichtigung aller Informationen im Prompt kann das LLM eine spezifische Antwort auf die Frage formulieren -> Retrieval Augmented Generation.
Diesen Ansatz haben wir im Zuge eines Camps umgesetzt. Es entstanden drei in unsere Systeme integrierte Assistenten, die Mitarbeitende die Suche nach Interna erleichtern können. Mehr dazu in diesem Artikel: Camp 2024 – Knowledge Base 2.0 mit RAG.
Fazit
Konzepte zum Umgang mit Geschäftsdaten sind Teil jedweder Digitalisierungsstrategie. Mit generativer KI in Form von LLMs wird zuletzt auch der Zugang zu Daten verstärkt neu gedacht.
RAG sowie die barrierefreie Integration dieses Ansatzes in beliebige Datensysteme, wie z.B. in unternehmensinterne Kommunikations- und Informations-Plattformen hat großes Potential, den Konsum von Wissen für Nutzer:innen noch weiter zu vereinfachen. Die Umsetzung ist dabei verhältnismäßig einfach. Hierzu notwendige Services wie Sprachmodelle, Vektor-Datenbanken, Speech Services etc. haben einen hohen Reifegrad erreicht, sind problemlos einzubinden und werden durch viele Provider angeboten.
Daher ist zu erwarten, dass RAG in Verbindung mit sprach-basierten Assistenten in kürzester Zeit in vielen – wenn nicht allen – Content-Plattformen integriert sein wird und sich diese Form der Datensuche in einigen Bereichen als Hauptnutzungsart durchsetzen wird.

Head of Technology